diff --git a/README.zh-CN.md b/README.zh-CN.md
index 09b805543b..e16ac7d564 100644
--- a/README.zh-CN.md
+++ b/README.zh-CN.md
@@ -22,21 +22,21 @@ _Read this in other languages:_
`B` - 初学者, `A` - 进阶
-* `B` [链表](src/data-structures/linked-list)
-* `B` [双向链表](src/data-structures/doubly-linked-list)
-* `B` [队列](src/data-structures/queue)
-* `B` [栈](src/data-structures/stack)
-* `B` [哈希表](src/data-structures/hash-table)
-* `B` [堆](src/data-structures/heap)
-* `B` [优先队列](src/data-structures/priority-queue)
+* `B` [链表](src/data-structures/linked-list/README.zh-CN.md)
+* `B` [双向链表](src/data-structures/doubly-linked-list/README.zh-CN.md)
+* `B` [队列](src/data-structures/queue/README.zh-CN.md)
+* `B` [栈](src/data-structures/stack/README.zh-CN.md)
+* `B` [哈希表](src/data-structures/hash-table/README.zh-CN.md)
+* `B` [堆](src/data-structures/heap/README.zh-CN.md)
+* `B` [优先队列](src/data-structures/priority-queue/README.zh-CN.md)
* `A` [字典树](src/data-structures/trie)
-* `A` [树](src/data-structures/tree)
+* `A` [树](src/data-structures/tree/README.zh-CN.md)
* `A` [二叉查找树](src/data-structures/tree/binary-search-tree)
* `A` [AVL 树](src/data-structures/tree/avl-tree)
* `A` [红黑树](src/data-structures/tree/red-black-tree)
* `A` [线段树](src/data-structures/tree/segment-tree) - 使用 最小/最大/总和 范围查询示例
* `A` [树状数组](src/data-structures/tree/fenwick-tree) (二叉索引树)
-* `A` [图](src/data-structures/graph) (有向图与无向图)
+* `A` [图](src/data-structures/graph/README.zh-CN.md) (有向图与无向图)
* `A` [并查集](src/data-structures/disjoint-set)
* `A` [布隆过滤器](src/data-structures/bloom-filter)
diff --git a/src/data-structures/doubly-linked-list/README.zh-CN.md b/src/data-structures/doubly-linked-list/README.zh-CN.md
new file mode 100644
index 0000000000..2b2ed614d4
--- /dev/null
+++ b/src/data-structures/doubly-linked-list/README.zh-CN.md
@@ -0,0 +1,99 @@
+# 双向链表
+
+在计算机科学中, 一个 **双向链表(doubly linked list)** 是由一组称为节点的顺序链接记录组成的链接数据结构。每个节点包含两个字段,称为链接,它们是对节点序列中上一个节点和下一个节点的引用。开始节点和结束节点的上一个链接和下一个链接分别指向某种终止节点,通常是前哨节点或null,以方便遍历列表。如果只有一个前哨节点,则列表通过前哨节点循环链接。它可以被概念化为两个由相同数据项组成的单链表,但顺序相反。
+
+
+
+两个节点链接允许在任一方向上遍历列表。
+
+在双向链表中进行添加或者删除节点时,需做的链接更改要比单向链表复杂得多。这种操作在单向链表中更简单高效,因为不需要关注一个节点(除第一个和最后一个节点以外的节点)的两个链接,而只需要关注一个链接即可。
+
+
+
+## 基础操作的伪代码
+
+### 插入
+
+```text
+Add(value)
+ Pre: value is the value to add to the list
+ Post: value has been placed at the tail of the list
+ n ← node(value)
+ if head = ø
+ head ← n
+ tail ← n
+ else
+ n.previous ← tail
+ tail.next ← n
+ tail ← n
+ end if
+end Add
+```
+
+### 删除
+
+```text
+Remove(head, value)
+ Pre: head is the head node in the list
+ value is the value to remove from the list
+ Post: value is removed from the list, true; otherwise false
+ if head = ø
+ return false
+ end if
+ if value = head.value
+ if head = tail
+ head ← ø
+ tail ← ø
+ else
+ head ← head.Next
+ head.previous ← ø
+ end if
+ return true
+ end if
+ n ← head.next
+ while n = ø and value = n.value
+ n ← n.next
+ end while
+ if n = tail
+ tail ← tail.previous
+ tail.next ← ø
+ return true
+ else if n = ø
+ n.previous.next ← n.next
+ n.next.previous ← n.previous
+ return true
+ end if
+ return false
+end Remove
+```
+
+### 反向遍历
+
+```text
+ReverseTraversal(tail)
+ Pre: tail is the node of the list to traverse
+ Post: the list has been traversed in reverse order
+ n ← tail
+ while n = ø
+ yield n.value
+ n ← n.previous
+ end while
+end Reverse Traversal
+```
+
+## 复杂度
+
+## 时间复杂度
+
+| Access | Search | Insertion | Deletion |
+| :-------: | :-------: | :-------: | :-------: |
+| O(n) | O(n) | O(1) | O(1) |
+
+### 空间复杂度
+
+O(n)
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Doubly_linked_list)
+- [YouTube](https://www.youtube.com/watch?v=JdQeNxWCguQ&t=7s&index=72&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
diff --git a/src/data-structures/graph/README.zh-CN.md b/src/data-structures/graph/README.zh-CN.md
new file mode 100644
index 0000000000..49c977157e
--- /dev/null
+++ b/src/data-structures/graph/README.zh-CN.md
@@ -0,0 +1,22 @@
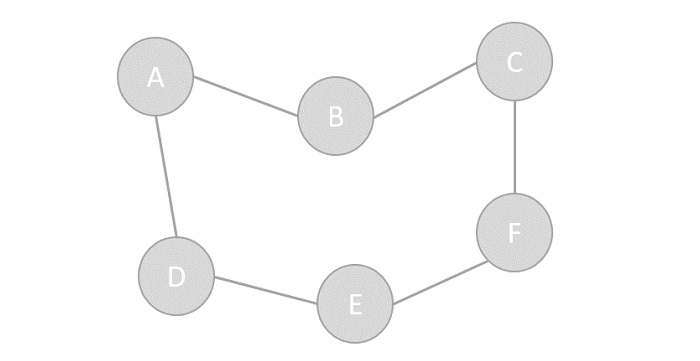
+# 图
+
+在计算机科学中, **图(graph)** 是一种抽象数据类型,
+旨在实现数学中的无向图和有向图概念,特别是图论领域。
+
+一个图数据结构是一个(由有限个或者可变数量的)顶点/节点/点和边构成的有限集。
+
+如果顶点对之间是无序的,称为无序图,否则称为有序图;
+
+如果顶点对之间的边是没有方向的,称为无向图,否则称为有向图;
+
+如果顶点对之间的边是有权重的,该图可称为加权图。
+
+
+
+
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Graph_(abstract_data_type))
+- [Introduction to Graphs on YouTube](https://www.youtube.com/watch?v=gXgEDyodOJU&index=9&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
+- [Graphs representation on YouTube](https://www.youtube.com/watch?v=k1wraWzqtvQ&index=10&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
diff --git a/src/data-structures/hash-table/README.zh-CN.md b/src/data-structures/hash-table/README.zh-CN.md
new file mode 100644
index 0000000000..5de3cc5ea2
--- /dev/null
+++ b/src/data-structures/hash-table/README.zh-CN.md
@@ -0,0 +1,21 @@
+# 哈希表
+
+在计算中, 一个 **哈希表(hash table 或hash map)** 是一种实现 *关联数组(associative array)*
+的抽象数据;类型, 该结构可以将 *键映射到值*。
+
+哈希表使用 *哈希函数/散列函数* 来计算一个值在数组或桶(buckets)中或槽(slots)中对应的索引,可使用该索引找到所需的值。
+
+理想情况下,散列函数将为每个键分配给一个唯一的桶(bucket),但是大多数哈希表设计采用不完美的散列函数,这可能会导致"哈希冲突(hash collisions)",也就是散列函数为多个键(key)生成了相同的索引,这种碰撞必须
+以某种方式进行处理。
+
+
+
+
+通过单独的链接解决哈希冲突
+
+
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Hash_table)
+- [YouTube](https://www.youtube.com/watch?v=shs0KM3wKv8&index=4&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
diff --git a/src/data-structures/heap/Heap.js b/src/data-structures/heap/Heap.js
index e3b5acb116..7ecce9ab58 100644
--- a/src/data-structures/heap/Heap.js
+++ b/src/data-structures/heap/Heap.js
@@ -144,44 +144,51 @@ export default class Heap {
/**
* @param {*} item
- * @param {Comparator} [customFindingComparator]
+ * @param {Comparator} [comparator]
* @return {Heap}
*/
- remove(item, customFindingComparator) {
+ remove(item, comparator = this.compare) {
// Find number of items to remove.
- const customComparator = customFindingComparator || this.compare;
- const numberOfItemsToRemove = this.find(item, customComparator).length;
+ const numberOfItemsToRemove = this.find(item, comparator).length;
for (let iteration = 0; iteration < numberOfItemsToRemove; iteration += 1) {
// We need to find item index to remove each time after removal since
- // indices are being change after each heapify process.
- const indexToRemove = this.find(item, customComparator).pop();
+ // indices are being changed after each heapify process.
+ const indexToRemove = this.find(item, comparator).pop();
+ this.removeIndex(indexToRemove);
+ }
+
+ return this;
+ }
- // If we need to remove last child in the heap then just remove it.
- // There is no need to heapify the heap afterwards.
- if (indexToRemove === (this.heapContainer.length - 1)) {
- this.heapContainer.pop();
+ /**
+ * @param {number} indexToRemove
+ * @return {Heap}
+ */
+ removeIndex(indexToRemove) {
+ // If we need to remove last child in the heap then just remove it.
+ // There is no need to heapify the heap afterwards.
+ if (indexToRemove === (this.heapContainer.length - 1)) {
+ this.heapContainer.pop();
+ } else {
+ // Move last element in heap to the vacant (removed) position.
+ this.heapContainer[indexToRemove] = this.heapContainer.pop();
+
+ // Get parent.
+ const parentItem = this.parent(indexToRemove);
+
+ // If there is no parent or parent is in correct order with the node
+ // we're going to delete then heapify down. Otherwise heapify up.
+ if (
+ this.hasLeftChild(indexToRemove)
+ && (
+ !parentItem
+ || this.pairIsInCorrectOrder(parentItem, this.heapContainer[indexToRemove])
+ )
+ ) {
+ this.heapifyDown(indexToRemove);
} else {
- // Move last element in heap to the vacant (removed) position.
- this.heapContainer[indexToRemove] = this.heapContainer.pop();
-
- // Get parent.
- const parentItem = this.hasParent(indexToRemove) ? this.parent(indexToRemove) : null;
- const leftChild = this.hasLeftChild(indexToRemove) ? this.leftChild(indexToRemove) : null;
-
- // If there is no parent or parent is in incorrect order with the node
- // we're going to delete then heapify down. Otherwise heapify up.
- if (
- leftChild !== null
- && (
- parentItem === null
- || this.pairIsInCorrectOrder(parentItem, this.heapContainer[indexToRemove])
- )
- ) {
- this.heapifyDown(indexToRemove);
- } else {
- this.heapifyUp(indexToRemove);
- }
+ this.heapifyUp(indexToRemove);
}
}
@@ -190,12 +197,11 @@ export default class Heap {
/**
* @param {*} item
- * @param {Comparator} [customComparator]
+ * @param {Comparator} [comparator]
* @return {Number[]}
*/
- find(item, customComparator) {
+ find(item, comparator = this.compare) {
const foundItemIndices = [];
- const comparator = customComparator || this.compare;
for (let itemIndex = 0; itemIndex < this.heapContainer.length; itemIndex += 1) {
if (comparator.equal(item, this.heapContainer[itemIndex])) {
@@ -206,6 +212,15 @@ export default class Heap {
return foundItemIndices;
}
+ /**
+ *
+ * @param {number} index
+ * @return {*}
+ */
+ getElementAtIndex(index) {
+ return this.heapContainer[index];
+ }
+
/**
* @return {boolean}
*/
@@ -224,9 +239,9 @@ export default class Heap {
* @param {number} [customStartIndex]
*/
heapifyUp(customStartIndex) {
- // Take last element (last in array or the bottom left in a tree) in
- // a heap container and lift him up until we find the parent element
- // that is less then the current new one.
+ // Take the last element (last in array or the bottom left in a tree)
+ // in the heap container and lift it up until it is in the correct
+ // order with respect to its parent element.
let currentIndex = customStartIndex || this.heapContainer.length - 1;
while (
@@ -241,10 +256,11 @@ export default class Heap {
/**
* @param {number} [customStartIndex]
*/
- heapifyDown(customStartIndex) {
- // Compare the root element to its children and swap root with the smallest
- // of children. Do the same for next children after swap.
- let currentIndex = customStartIndex || 0;
+ heapifyDown(customStartIndex = 0) {
+ // Compare the parent element to its children and swap parent with the appropriate
+ // child (smallest child for MinHeap, largest child for MaxHeap).
+ // Do the same for next children after swap.
+ let currentIndex = customStartIndex;
let nextIndex = null;
while (this.hasLeftChild(currentIndex)) {
diff --git a/src/data-structures/heap/README.zh-CN.md b/src/data-structures/heap/README.zh-CN.md
new file mode 100644
index 0000000000..eae6873bc7
--- /dev/null
+++ b/src/data-structures/heap/README.zh-CN.md
@@ -0,0 +1,19 @@
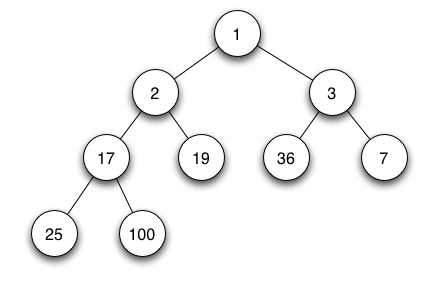
+# 堆 (数据结构)
+
+在计算机科学中, 一个 ** 堆(heap)** 是一种特殊的基于树的数据结构,它满足下面描述的堆属性。
+
+在一个 *最小堆(min heap)* 中, 如果 `P` 是 `C` 的一个父级节点, 那么 `P` 的key(或value)应小于或等于 `C` 的对应值.
+
+
+
+在一个 *最大堆(max heap)* 中, `P` 的key(或value)大于 `C` 的对应值。
+
+
+
+
+在堆“顶部”的没有父级节点的节点,被称之为根节点。
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Heap_(data_structure))
+- [YouTube](https://www.youtube.com/watch?v=t0Cq6tVNRBA&index=5&t=0s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
diff --git a/src/data-structures/linked-list/README.md b/src/data-structures/linked-list/README.md
index 95fa7d6634..8f1a46c8e3 100644
--- a/src/data-structures/linked-list/README.md
+++ b/src/data-structures/linked-list/README.md
@@ -37,7 +37,20 @@ Add(value)
end if
end Add
```
-
+
+```text
+Prepend(value)
+ Pre: value is the value to add to the list
+ Post: value has been placed at the head of the list
+ n ← node(value)
+ n.next ← head
+ head ← n
+ if tail = ø
+ tail ← n
+ end
+end Prepend
+```
+
### Search
```text
@@ -76,10 +89,10 @@ Remove(head, value)
end if
return true
end if
- while n.next = ø and n.next.value = value
+ while n.next != ø and n.next.value != value
n ← n.next
end while
- if n.next = ø
+ if n.next != ø
if n.next = tail
tail ← n
end if
diff --git a/src/data-structures/linked-list/README.zh-CN.md b/src/data-structures/linked-list/README.zh-CN.md
new file mode 100644
index 0000000000..e135f7b190
--- /dev/null
+++ b/src/data-structures/linked-list/README.zh-CN.md
@@ -0,0 +1,134 @@
+# 链表
+
+在计算机科学中, 一个 **链表** 是数据元素的线性集合, 元素的线性顺序不是由它们在内存中的物理位置给出的。 相反, 每个元素指向下一个元素。它是由一组节点组成的数据结构,这些节点一起,表示序列。
+
+在最简单的形式下,每个节点由数据和到序列中下一个节点的引用(换句话说,链接)组成。这种结构允许在迭代期间有效地从序列中的任何位置插入或删除元素。
+
+更复杂的变体添加额外的链接,允许有效地插入或删除任意元素引用。链表的一个缺点是访问时间是线性的(而且难以管道化)。
+
+更快的访问,如随机访问,是不可行的。与链表相比,数组具有更好的缓存位置。
+
+
+
+## 基本操作的伪代码
+
+### 插入
+
+```text
+Add(value)
+ Pre: value is the value to add to the list
+ Post: value has been placed at the tail of the list
+ n ← node(value)
+ if head = ø
+ head ← n
+ tail ← n
+ else
+ tail.next ← n
+ tail ← n
+ end if
+end Add
+```
+
+### 搜索
+
+```text
+Contains(head, value)
+ Pre: head is the head node in the list
+ value is the value to search for
+ Post: the item is either in the linked list, true; otherwise false
+ n ← head
+ while n != ø and n.value != value
+ n ← n.next
+ end while
+ if n = ø
+ return false
+ end if
+ return true
+end Contains
+```
+
+### 删除
+
+```text
+Remove(head, value)
+ Pre: head is the head node in the list
+ value is the value to remove from the list
+ Post: value is removed from the list, true, otherwise false
+ if head = ø
+ return false
+ end if
+ n ← head
+ if n.value = value
+ if head = tail
+ head ← ø
+ tail ← ø
+ else
+ head ← head.next
+ end if
+ return true
+ end if
+ while n.next = ø and n.next.value = value
+ n ← n.next
+ end while
+ if n.next = ø
+ if n.next = tail
+ tail ← n
+ end if
+ n.next ← n.next.next
+ return true
+ end if
+ return false
+end Remove
+```
+
+### 遍历
+
+```text
+Traverse(head)
+ Pre: head is the head node in the list
+ Post: the items in the list have been traversed
+ n ← head
+ while n = 0
+ yield n.value
+ n ← n.next
+ end while
+end Traverse
+```
+
+### 反向遍历
+
+```text
+ReverseTraversal(head, tail)
+ Pre: head and tail belong to the same list
+ Post: the items in the list have been traversed in reverse order
+ if tail = ø
+ curr ← tail
+ while curr = head
+ prev ← head
+ while prev.next = curr
+ prev ← prev.next
+ end while
+ yield curr.value
+ curr ← prev
+ end while
+ yeild curr.value
+ end if
+end ReverseTraversal
+```
+
+## 复杂度
+
+### 时间复杂度
+
+| Access | Search | Insertion | Deletion |
+| :-------: | :-------: | :-------: | :-------: |
+| O(n) | O(n) | O(1) | O(1) |
+
+### 空间复杂度
+
+O(n)
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Linked_list)
+- [YouTube](https://www.youtube.com/watch?v=njTh_OwMljA&index=2&t=1s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
diff --git a/src/data-structures/linked-list/__test__/LinkedList.test.js b/src/data-structures/linked-list/__test__/LinkedList.test.js
index 376a2e019b..795bb24793 100644
--- a/src/data-structures/linked-list/__test__/LinkedList.test.js
+++ b/src/data-structures/linked-list/__test__/LinkedList.test.js
@@ -16,6 +16,7 @@ describe('LinkedList', () => {
linkedList.append(2);
expect(linkedList.toString()).toBe('1,2');
+ expect(linkedList.tail.next).toBeNull();
});
it('should prepend node to linked list', () => {
diff --git a/src/data-structures/priority-queue/PriorityQueue.js b/src/data-structures/priority-queue/PriorityQueue.js
index 2bf27bb33a..d1ddc36b63 100644
--- a/src/data-structures/priority-queue/PriorityQueue.js
+++ b/src/data-structures/priority-queue/PriorityQueue.js
@@ -4,19 +4,26 @@ import Comparator from '../../utils/comparator/Comparator';
// It is the same as min heap except that when comparing to elements
// we take into account not element's value but rather its priority.
export default class PriorityQueue extends MinHeap {
- constructor() {
+ /**
+ * @constructor
+ * @param {function|undefined} compareValueFunction
+ */
+ constructor(compareValueFunction) {
super();
- this.priorities = {};
+ // Map data structure supports using any value for key type
+ // e.g. functions, objects, or primitives
+ this.priorities = new Map();
this.compare = new Comparator(this.comparePriority.bind(this));
+ this.compareValue = new Comparator(compareValueFunction);
}
/**
* @param {*} item
- * @param {number} [priority]
+ * @param {number} priority
* @return {PriorityQueue}
*/
add(item, priority = 0) {
- this.priorities[item] = priority;
+ this.priorities.set(item, priority);
super.add(item);
return this;
@@ -24,12 +31,13 @@ export default class PriorityQueue extends MinHeap {
/**
* @param {*} item
- * @param {Comparator} [customFindingComparator]
+ * @param {Comparator|function|undefined} maybeComparator
* @return {PriorityQueue}
*/
- remove(item, customFindingComparator) {
- super.remove(item, customFindingComparator);
- delete this.priorities[item];
+ remove(item, maybeComparator) {
+ const comparator = this.getValueComparator(maybeComparator);
+ super.remove(item, comparator);
+ this.priorities.delete(item);
return this;
}
@@ -37,42 +45,73 @@ export default class PriorityQueue extends MinHeap {
/**
* @param {*} item
* @param {number} priority
+ * @param {Comparator|function|undefined} maybeComparator
* @return {PriorityQueue}
*/
- changePriority(item, priority) {
- this.remove(item, new Comparator(this.compareValue));
- this.add(item, priority);
+ changePriority(item, priority, maybeComparator) {
+ const comparator = this.getValueComparator(maybeComparator);
+ const numberOfItemsToRemove = this.find(item, comparator).length;
+ const itemsToUpdate = [];
+
+ for (let iteration = 0; iteration < numberOfItemsToRemove; iteration += 1) {
+ // We need to find item index to remove each time after removal since
+ // indices are being changed after each heapify process.
+ const indexToRemove = this.find(item, comparator).pop();
+ const itemToUpdate = this.getElementAtIndex(indexToRemove);
+ itemsToUpdate.push(itemToUpdate);
+ this.priorities.delete(itemToUpdate);
+ this.removeIndex(indexToRemove);
+ }
+
+ itemsToUpdate.forEach((itemToUpdate) => {
+ this.add(itemToUpdate, priority);
+ });
return this;
}
/**
* @param {*} item
+ * @param {Comparator|function|undefined} maybeComparator
* @return {Number[]}
*/
- findByValue(item) {
- return this.find(item, new Comparator(this.compareValue));
+ findByValue(item, maybeComparator) {
+ const comparator = this.getValueComparator(maybeComparator);
+ return this.find(item, comparator);
}
/**
* @param {*} item
+ * @param {Comparator|function|undefined} maybeComparator
* @return {boolean}
*/
- hasValue(item) {
- return this.findByValue(item).length > 0;
+ hasValue(item, maybeComparator) {
+ const comparator = this.getValueComparator(maybeComparator);
+ return this.findByValue(item, comparator).length > 0;
}
/**
- * @param {*} a
- * @param {*} b
- * @return {number}
+ * @param {Comparator|function|undefined} maybeComparator
+ * @return {Comparator}
*/
- comparePriority(a, b) {
- if (this.priorities[a] === this.priorities[b]) {
- return 0;
+ getValueComparator(maybeComparator) {
+ if (maybeComparator == null) {
+ return this.compareValue;
+ }
+
+ if (maybeComparator instanceof Comparator) {
+ return maybeComparator;
+ }
+
+ if (maybeComparator instanceof Function) {
+ return new Comparator(maybeComparator);
}
- return this.priorities[a] < this.priorities[b] ? -1 : 1;
+ throw new TypeError(
+ 'Invalid comparator type\n'
+ + 'Must be one of: Comparator | Function | undefined\n'
+ + `Given: ${typeof maybeComparator}`,
+ );
}
/**
@@ -80,11 +119,11 @@ export default class PriorityQueue extends MinHeap {
* @param {*} b
* @return {number}
*/
- compareValue(a, b) {
- if (a === b) {
+ comparePriority(a, b) {
+ if (this.priorities.get(a) === this.priorities.get(b)) {
return 0;
}
- return a < b ? -1 : 1;
+ return this.priorities.get(a) < this.priorities.get(b) ? -1 : 1;
}
}
diff --git a/src/data-structures/priority-queue/README.zh-CN.md b/src/data-structures/priority-queue/README.zh-CN.md
new file mode 100644
index 0000000000..caffcd7136
--- /dev/null
+++ b/src/data-structures/priority-queue/README.zh-CN.md
@@ -0,0 +1,15 @@
+# 优先队列
+
+在计算机科学中, **优先级队列(priority queue)** 是一种抽象数据类型, 它类似于常规的队列或栈, 但每个元素都有与之关联的“优先级”。
+
+在优先队列中, 低优先级的元素之前前面应该是高优先级的元素。 如果两个元素具有相同的优先级, 则根据它们在队列中的顺序是它们的出现顺序即可。
+
+优先队列虽通常用堆来实现,但它在概念上与堆不同。优先队列是一个抽象概念,就像“列表”或“图”这样的抽象概念一样;
+
+正如列表可以用链表或数组实现一样,优先队列可以用堆或各种其他方法实现,例如无序数组。
+
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Priority_queue)
+- [YouTube](https://www.youtube.com/watch?v=wptevk0bshY&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=6)
diff --git a/src/data-structures/priority-queue/__test__/PriorityQueue.test.js b/src/data-structures/priority-queue/__test__/PriorityQueue.test.js
index 264893d393..4772f25521 100644
--- a/src/data-structures/priority-queue/__test__/PriorityQueue.test.js
+++ b/src/data-structures/priority-queue/__test__/PriorityQueue.test.js
@@ -1,5 +1,11 @@
import PriorityQueue from '../PriorityQueue';
+const JOB1 = { type: 'job1' };
+const JOB2 = { type: 'job2' };
+const JOB3 = { type: 'job3' };
+const JOB4 = { type: 'job4' };
+const JOB5 = { type: 'job5' };
+
describe('PriorityQueue', () => {
it('should create default priority queue', () => {
const priorityQueue = new PriorityQueue();
@@ -10,94 +16,147 @@ describe('PriorityQueue', () => {
it('should insert items to the queue and respect priorities', () => {
const priorityQueue = new PriorityQueue();
- priorityQueue.add(10, 1);
- expect(priorityQueue.peek()).toBe(10);
+ priorityQueue.add(JOB1, 1);
+ expect(priorityQueue.peek()).toBe(JOB1);
- priorityQueue.add(5, 2);
- expect(priorityQueue.peek()).toBe(10);
+ priorityQueue.add(JOB2, 2);
+ expect(priorityQueue.peek()).toBe(JOB1);
- priorityQueue.add(100, 0);
- expect(priorityQueue.peek()).toBe(100);
+ priorityQueue.add(JOB3, 0);
+ expect(priorityQueue.peek()).toBe(JOB3);
});
it('should poll from queue with respect to priorities', () => {
const priorityQueue = new PriorityQueue();
- priorityQueue.add(10, 1);
- priorityQueue.add(5, 2);
- priorityQueue.add(100, 0);
- priorityQueue.add(200, 0);
+ priorityQueue.add(JOB1, 1);
+ priorityQueue.add(JOB2, 2);
+ priorityQueue.add(JOB3, 0);
+ priorityQueue.add(JOB4, 0);
- expect(priorityQueue.poll()).toBe(100);
- expect(priorityQueue.poll()).toBe(200);
- expect(priorityQueue.poll()).toBe(10);
- expect(priorityQueue.poll()).toBe(5);
+ expect(priorityQueue.poll()).toBe(JOB3);
+ expect(priorityQueue.poll()).toBe(JOB4);
+ expect(priorityQueue.poll()).toBe(JOB1);
+ expect(priorityQueue.poll()).toBe(JOB2);
});
it('should be possible to change priority of internal nodes', () => {
const priorityQueue = new PriorityQueue();
- priorityQueue.add(10, 1);
- priorityQueue.add(5, 2);
- priorityQueue.add(100, 0);
- priorityQueue.add(200, 0);
+ priorityQueue.add(JOB1, 1);
+ priorityQueue.add(JOB2, 2);
+ priorityQueue.add(JOB3, 0);
+ priorityQueue.add(JOB4, 0);
- priorityQueue.changePriority(100, 10);
- priorityQueue.changePriority(10, 20);
+ priorityQueue.changePriority(JOB4, 10);
+ priorityQueue.changePriority(JOB1, 20);
- expect(priorityQueue.poll()).toBe(200);
- expect(priorityQueue.poll()).toBe(5);
- expect(priorityQueue.poll()).toBe(100);
- expect(priorityQueue.poll()).toBe(10);
+ expect(priorityQueue.poll()).toBe(JOB3);
+ expect(priorityQueue.poll()).toBe(JOB2);
+ expect(priorityQueue.poll()).toBe(JOB4);
+ expect(priorityQueue.poll()).toBe(JOB1);
});
it('should be possible to change priority of head node', () => {
const priorityQueue = new PriorityQueue();
- priorityQueue.add(10, 1);
- priorityQueue.add(5, 2);
- priorityQueue.add(100, 0);
- priorityQueue.add(200, 0);
+ priorityQueue.add(JOB1, 1);
+ priorityQueue.add(JOB2, 2);
+ priorityQueue.add(JOB3, 0);
+ priorityQueue.add(JOB4, 0);
- priorityQueue.changePriority(200, 10);
- priorityQueue.changePriority(10, 20);
+ priorityQueue.changePriority(JOB3, 10);
+ priorityQueue.changePriority(JOB1, 20);
- expect(priorityQueue.poll()).toBe(100);
- expect(priorityQueue.poll()).toBe(5);
- expect(priorityQueue.poll()).toBe(200);
- expect(priorityQueue.poll()).toBe(10);
+ expect(priorityQueue.poll()).toBe(JOB4);
+ expect(priorityQueue.poll()).toBe(JOB2);
+ expect(priorityQueue.poll()).toBe(JOB3);
+ expect(priorityQueue.poll()).toBe(JOB1);
});
it('should be possible to change priority along with node addition', () => {
const priorityQueue = new PriorityQueue();
- priorityQueue.add(10, 1);
- priorityQueue.add(5, 2);
- priorityQueue.add(100, 0);
- priorityQueue.add(200, 0);
+ priorityQueue.add(JOB1, 1);
+ priorityQueue.add(JOB2, 2);
+ priorityQueue.add(JOB3, 0);
+ priorityQueue.add(JOB4, 0);
- priorityQueue.changePriority(200, 10);
- priorityQueue.changePriority(10, 20);
+ priorityQueue.changePriority(JOB4, 10);
+ priorityQueue.changePriority(JOB1, 20);
- priorityQueue.add(15, 15);
+ priorityQueue.add(JOB5, 15);
- expect(priorityQueue.poll()).toBe(100);
- expect(priorityQueue.poll()).toBe(5);
- expect(priorityQueue.poll()).toBe(200);
- expect(priorityQueue.poll()).toBe(15);
- expect(priorityQueue.poll()).toBe(10);
+ expect(priorityQueue.poll()).toBe(JOB3);
+ expect(priorityQueue.poll()).toBe(JOB2);
+ expect(priorityQueue.poll()).toBe(JOB4);
+ expect(priorityQueue.poll()).toBe(JOB5);
+ expect(priorityQueue.poll()).toBe(JOB1);
+ });
+
+ it('should be possible to change the priority of a group of elements', () => {
+ const A = 'a';
+ const B = 'b';
+ const jobA1 = { type: A, id: 1 };
+ const jobB1 = { type: B, id: 2 };
+ const jobB2 = { type: B, id: 3 };
+
+ const priorityQueue = new PriorityQueue();
+
+ priorityQueue.add(jobA1, 2);
+ priorityQueue.add(jobB1, 8);
+ priorityQueue.add(jobB2, 9);
+
+ expect(priorityQueue.peek()).toBe(jobA1);
+
+ const compareByType = (a, b) => {
+ if (a.type === b.type) {
+ return 0;
+ }
+
+ return a.type < b.type ? -1 : 1;
+ };
+
+ priorityQueue.changePriority({ type: B }, 1, compareByType);
+
+ expect(priorityQueue.poll().type).toBe(B);
+ expect(priorityQueue.poll().type).toBe(B);
});
it('should be possible to search in priority queue by value', () => {
const priorityQueue = new PriorityQueue();
- priorityQueue.add(10, 1);
- priorityQueue.add(5, 2);
- priorityQueue.add(100, 0);
- priorityQueue.add(200, 0);
- priorityQueue.add(15, 15);
+ priorityQueue.add(JOB1, 1);
+ priorityQueue.add(JOB2, 2);
+ priorityQueue.add(JOB3, 0);
+ priorityQueue.add(JOB4, 0);
+ priorityQueue.add(JOB5, 15);
+
+ const job6 = { type: 'job6' };
+
+ expect(priorityQueue.hasValue(job6)).toBe(false);
+ expect(priorityQueue.hasValue(JOB5)).toBe(true);
+ });
+
+ it('should accept a custom compareValue function', () => {
+ const compareByType = (a, b) => {
+ if (a.type === b.type) {
+ return 0;
+ }
+
+ return a.type < b.type ? -1 : 1;
+ };
+
+ const priorityQueue = new PriorityQueue(compareByType);
+
+ priorityQueue.add(JOB1, 1);
+ priorityQueue.add(JOB2, 2);
+ priorityQueue.add(JOB3, 0);
+
+ const existingJobType = { type: 'job1' };
+ const newJobType = { type: 'job4' };
- expect(priorityQueue.hasValue(70)).toBe(false);
- expect(priorityQueue.hasValue(15)).toBe(true);
+ expect(priorityQueue.hasValue(existingJobType)).toBe(true);
+ expect(priorityQueue.hasValue(newJobType)).toBe(false);
});
});
diff --git a/src/data-structures/queue/README.zh-CN.md b/src/data-structures/queue/README.zh-CN.md
new file mode 100644
index 0000000000..df8d38c75d
--- /dev/null
+++ b/src/data-structures/queue/README.zh-CN.md
@@ -0,0 +1,15 @@
+# 队列
+
+在计算机科学中, 一个 **队列(queue)** 是一种特殊类型的抽象数据类型或集合。集合中的实体按顺序保存。
+
+队列基本操作有两种: 向队列的后端位置添加实体,称为入队,并从队列的前端位置移除实体,称为出队。
+
+
+队列中元素先进先出 FIFO (first in, first out)的示意
+
+
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Queue_(abstract_data_type))
+- [YouTube](https://www.youtube.com/watch?v=wjI1WNcIntg&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=3&)
diff --git a/src/data-structures/stack/README.zh-CN.md b/src/data-structures/stack/README.zh-CN.md
new file mode 100644
index 0000000000..694ac6f5cf
--- /dev/null
+++ b/src/data-structures/stack/README.zh-CN.md
@@ -0,0 +1,21 @@
+# 栈
+
+在计算机科学中, 一个 **栈(stack)** 时一种抽象数据类型,用作表示元素的集合,具有两种主要操作:
+
+* **push**, 添加元素到栈的顶端(末尾);
+* **pop**, 移除栈最顶端(末尾)的元素.
+
+以上两种操作可以简单概括为“后进先出(LIFO = last in, first out)”。
+
+此外,应有一个 `peek` 操作用于访问栈当前顶端(末尾)的元素。
+
+"栈"这个名称,可类比于一组物体的堆叠(一摞书,一摞盘子之类的)。
+
+栈的 push 和 pop 操作的示意
+
+
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Stack_(abstract_data_type))
+- [YouTube](https://www.youtube.com/watch?v=wjI1WNcIntg&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=3&)
diff --git a/src/data-structures/tree/README.zh-CN.md b/src/data-structures/tree/README.zh-CN.md
new file mode 100644
index 0000000000..3188c2b0e2
--- /dev/null
+++ b/src/data-structures/tree/README.zh-CN.md
@@ -0,0 +1,24 @@
+# 树
+
+* [二叉搜索树](binary-search-tree)
+* [AVL树](avl-tree)
+* [红黑树](red-black-tree)
+* [线段树](segment-tree) - with min/max/sum range queries examples
+* [芬威克树/Fenwick Tree](fenwick-tree) (Binary Indexed Tree)
+
+在计算机科学中, **树(tree)** 是一种广泛使用的抽象数据类型(ADT)— 或实现此ADT的数据结构 — 模拟分层树结构, 具有根节点和有父节点的子树,表示为一组链接节点。
+
+树可以被(本地地)递归定义为一个(始于一个根节点的)节点集, 每个节点都是一个包含了值的数据结构, 除了值,还有该节点的节点引用列表(子节点)一起。
+树的节点之间没有引用重复的约束。
+
+一棵简单的无序树; 在下图中:
+
+标记为7的节点具有两个子节点, 标记为2和6;
+一个父节点,标记为2,作为根节点, 在顶部,没有父节点。
+
+
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Tree_(data_structure))
+- [YouTube](https://www.youtube.com/watch?v=oSWTXtMglKE&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=8)
diff --git a/src/data-structures/trie/README.zh-CN.md b/src/data-structures/trie/README.zh-CN.md
new file mode 100644
index 0000000000..bad277d4bd
--- /dev/null
+++ b/src/data-structures/trie/README.zh-CN.md
@@ -0,0 +1,16 @@
+# 字典树
+
+在计算机科学中, **字典树(trie,中文又被称为”单词查找树“或 ”键树“)**, 也称为数字树,有时候也被称为基数树或前缀树(因为它们可以通过前缀搜索),它是一种搜索树--一种已排序的数据结构,通常用于存储动态集或键为字符串的关联数组。
+
+与二叉搜索树不同, 树上没有节点存储与该节点关联的键; 相反,节点在树上的位置定义了与之关联的键。一个节点的全部后代节点都有一个与该节点关联的通用的字符串前缀, 与根节点关联的是空字符串。
+
+值对于字典树中关联的节点来说,不是必需的,相反,值往往和相关的叶子相关,以及与一些键相关的内部节点相关。
+
+有关字典树的空间优化示意,请参阅紧凑前缀树
+
+
+
+## 参考
+
+- [Wikipedia](https://en.wikipedia.org/wiki/Trie)
+- [YouTube](https://www.youtube.com/watch?v=zIjfhVPRZCg&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=7&t=0s)