|
| 1 | +# Counting Sort |
| 2 | + |
| 3 | +_Leia isso em outros idiomas:_ |
| 4 | +[_English_](README.md) |
| 5 | + |
| 6 | +Em ciência da computação, **counting sort** é um algoritmo para ordenar |
| 7 | +uma coleção de objetos de acordo com chaves que são pequenos inteiros; |
| 8 | +ou seja, é um algoritmo de ordenação de inteiros. Ele opera por |
| 9 | +contando o número de objetos que têm cada valor de chave distinto, |
| 10 | +e usando aritmética nessas contagens para determinar as posições |
| 11 | +de cada valor de chave na sequência de saída. Seu tempo de execução é |
| 12 | +linear no número de itens e a diferença entre o |
| 13 | +valores de chave máximo e mínimo, portanto, é adequado apenas para |
| 14 | +uso em situações em que a variação de tonalidades não é significativamente |
| 15 | +maior que o número de itens. No entanto, muitas vezes é usado como |
| 16 | +sub-rotina em outro algoritmo de ordenação, radix sort, que pode |
| 17 | +lidar com chaves maiores de forma mais eficiente. |
| 18 | + |
| 19 | +Como a classificação por contagem usa valores-chave como índices em um vetor, |
| 20 | +não é uma ordenação por comparação, e o limite inferior `Ω(n log n)` para |
| 21 | +a ordenação por comparação não se aplica a ele. A classificação por bucket pode ser usada |
| 22 | +para muitas das mesmas tarefas que a ordenação por contagem, com um tempo semelhante |
| 23 | +análise; no entanto, em comparação com a classificação por contagem, a classificação por bucket requer |
| 24 | +listas vinculadas, arrays dinâmicos ou uma grande quantidade de pré-alocados |
| 25 | +memória para armazenar os conjuntos de itens dentro de cada bucket, enquanto |
| 26 | +A classificação por contagem armazena um único número (a contagem de itens) |
| 27 | +por balde. |
| 28 | + |
| 29 | +A classificação por contagem funciona melhor quando o intervalo de números para cada |
| 30 | +elemento do vetor é muito pequeno. |
| 31 | + |
| 32 | +## Algoritmo |
| 33 | + |
| 34 | +**Passo I** |
| 35 | + |
| 36 | +Na primeira etapa, calculamos a contagem de todos os elementos do |
| 37 | +vetor de entrada 'A'. Em seguida, armazene o resultado no vetor de contagem `C`. |
| 38 | +A maneira como contamos é descrita abaixo. |
| 39 | + |
| 40 | +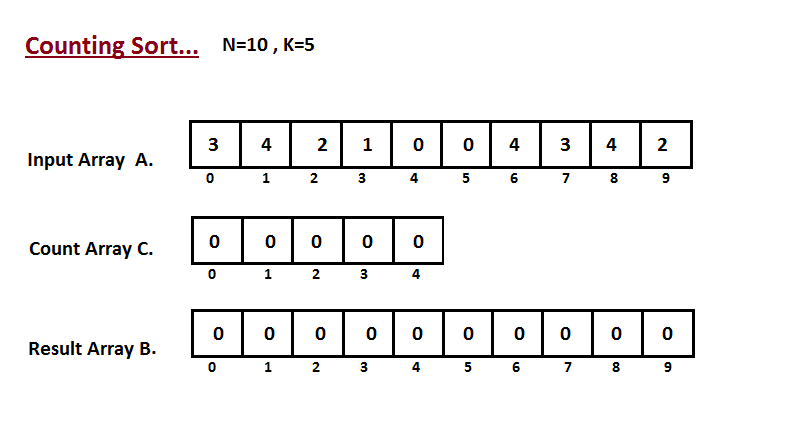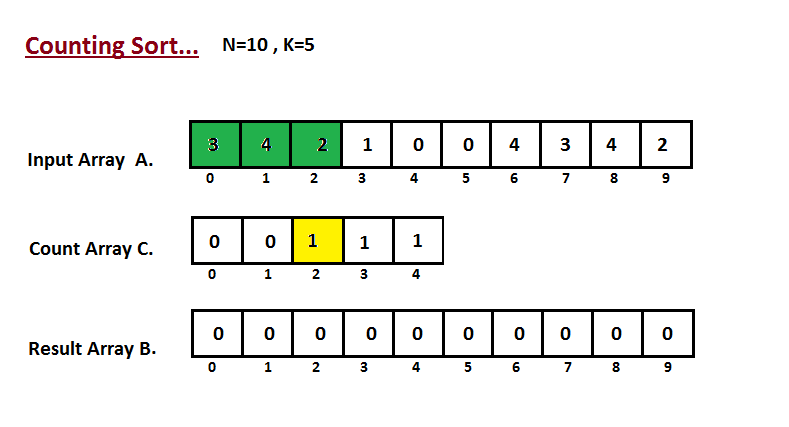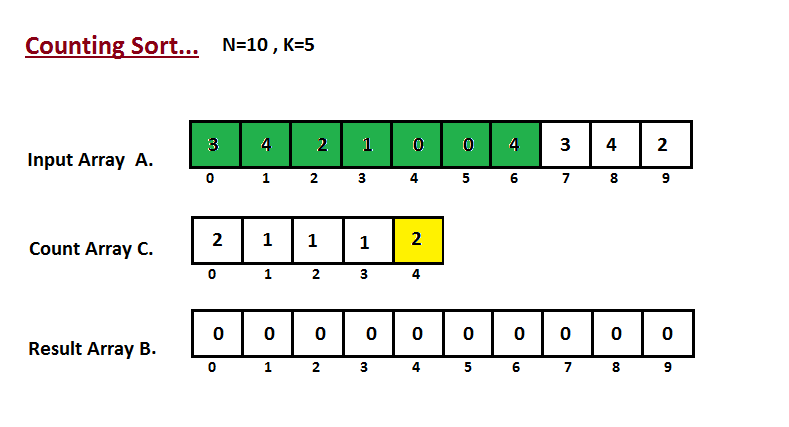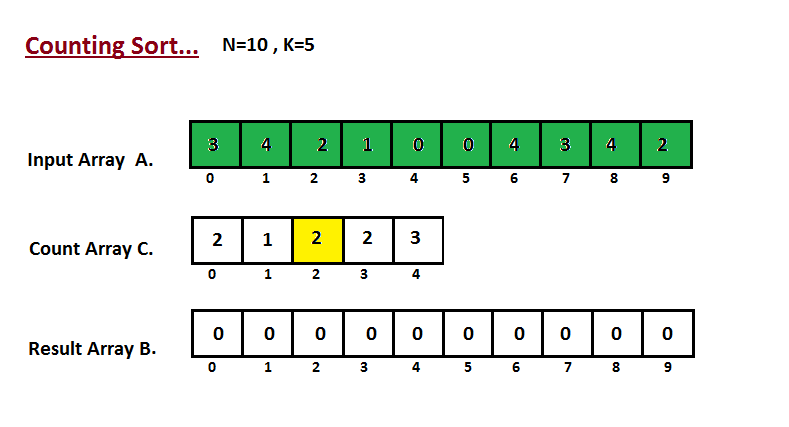 |
| 41 | + |
| 42 | +**Passo II** |
| 43 | + |
| 44 | +Na segunda etapa, calculamos quantos elementos existem na entrada |
| 45 | +do vetor `A` que são menores ou iguais para o índice fornecido. |
| 46 | +`Ci` = números de elementos menores ou iguais a `i` no vetor de entrada. |
| 47 | + |
| 48 | +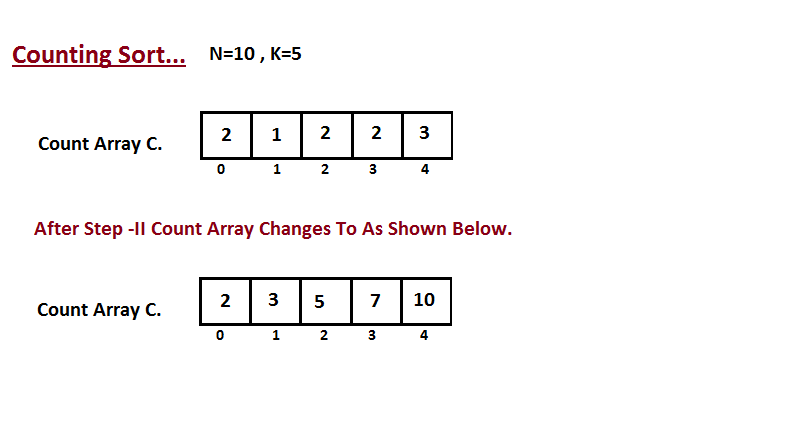 |
| 49 | + |
| 50 | +**Passo III** |
| 51 | + |
| 52 | +Nesta etapa, colocamos o elemento `A` do vetor de entrada em classificado |
| 53 | +posição usando a ajuda do vetor de contagem construída `C`, ou seja, o que |
| 54 | +construímos no passo dois. Usamos o vetor de resultados `B` para armazenar |
| 55 | +os elementos ordenados. Aqui nós lidamos com o índice de `B` começando de |
| 56 | +zero. |
| 57 | + |
| 58 | +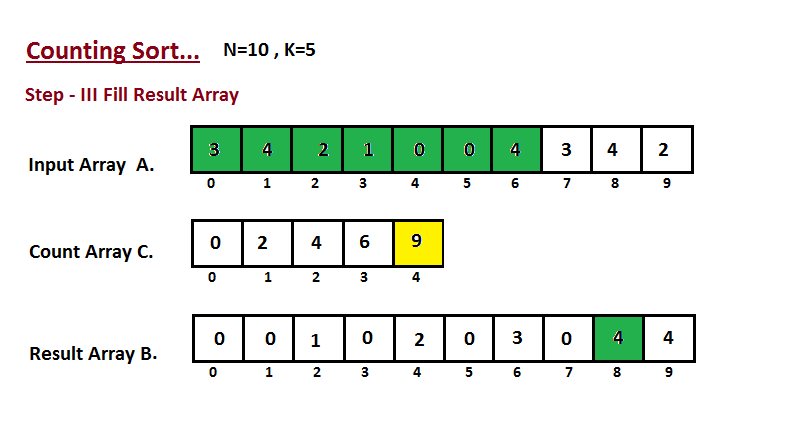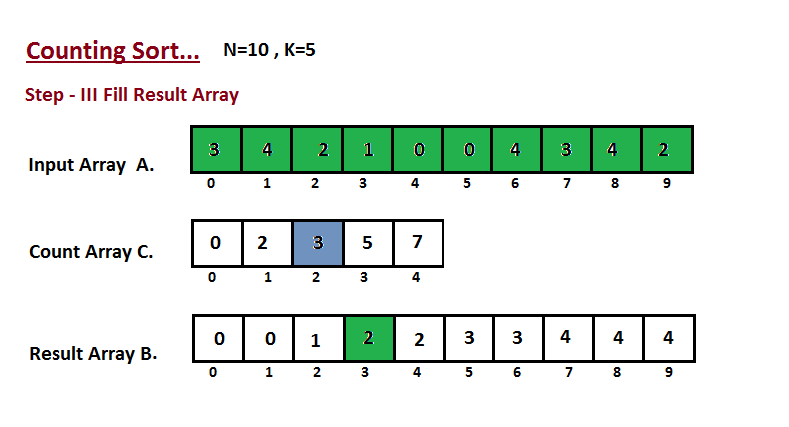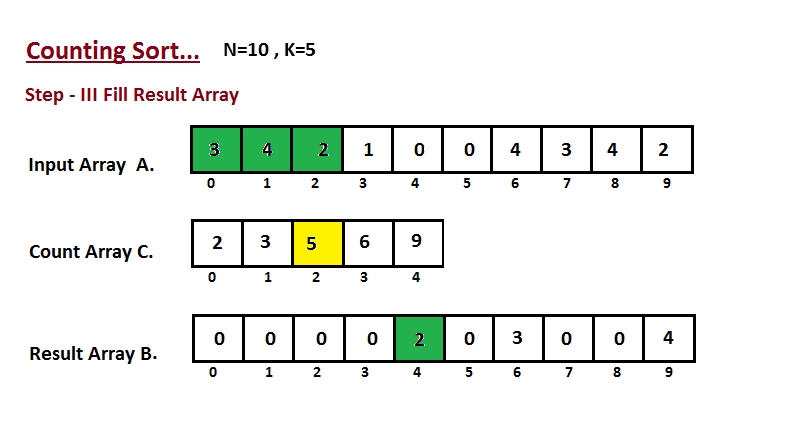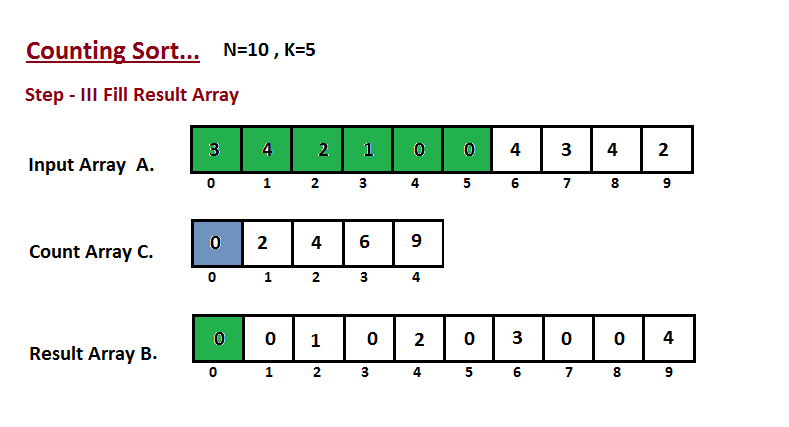 |
| 59 | + |
| 60 | +## Complexidade |
| 61 | + |
| 62 | +| Nome | Melhor | Média | Pior | Memória | Estável | Comentários | |
| 63 | +| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- | |
| 64 | +| **Counting sort** | n + r | n + r | n + r | n + r | Sim | r - Maior número no vetor | |
| 65 | + |
| 66 | +## Referências |
| 67 | + |
| 68 | +- [Wikipedia](https://en.wikipedia.org/wiki/Counting_sort) |
| 69 | +- [YouTube](https://www.youtube.com/watch?v=OKd534EWcdk&index=61&t=0s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) |
| 70 | +- [EfficientAlgorithms](https://efficientalgorithms.blogspot.com/2016/09/lenear-sorting-counting-sort.html) |
0 commit comments