| theme | lineNumbers | info |
|---|---|---|
academic |
true |
## Everything you didn't know you needed
Tips and tricks for python, shell and more
|
*blatant marketing nonsense
Kilian Lieret and Henry Schreiner
Princeton University
CoDaS-HEP school 2023
Slides available as open source, contributions welcome.
⁉️ Problem: Typing long server names and potentially tunnelling can be tiresome
- 💡Solution: Create configuration in
~/.ssh/config. You can even add pattern matching!
# Server I want to connect to
Host tiger*
Hostname tiger.princeton.edu
User kl5675
# Tunnel that I might use sometimes
Host tigressgateway
Hostname tigressgateway.princeton.edu
User kl5675
Host *-t
ProxyJump tigressgatewayNow you can use ssh tiger or ssh tiger-t depending on whether to tunnel or not.
⁉️ Problem: I already have an SSH session. How can I quickly forward a port?
-
💡Solution: SSH Escape Sequences:
- Hit Enter ~ C (now you should see a
ssh>prompt) - Add
-L 8000:localhost:8000Enter to forward port 8000 - More escape sequences available! More information.
- Hit Enter ~ C (now you should see a
-
Caveat: C option not available in multiplexed sessions.
- 💡 You can quickly search through your terminal history with Ctrl R - start typing
- Hit Ctrl R to navigate between different hits
- 🔥 Install fzf as a plugin to your shell to get an interactive fuzzy finding pop-up instead (interactively filter through list of results rather than just seeing one)
- 💡 You can reference the last word of the previous command with
!$
mkdir /path/to/some/directory/hello-world
cd !$- 💡 Want to fix up a complicated command that just failed? Type
fcto edit the command in your$EDITOR
- 💡 If you're using
bash, consider switching tozsh(almost completely compatible) and installoh-my-zshto get beautiful prompts, autocomplete on steroids and many small benefits
$ ~/D/P/x⇥
~/Document/Projects/xonsh/
$ part⇥
this-is-part-of-a-filename⁉️ Problem:manpages are wasting your time?
- 💡Solution: Try
tldr(pipx install tldr). Compare:


⁉️ Problem: Understanding cryptic bash commands
- 💡Solutions: Go to explainshell.com

⁉️ Problem: Changing directories in the terminal is cumbersome.
- 💡Solution: Autojump learns which directories you visit often. Hit
j <some part of directory name>to directly jump there - Installation instructions on github
Usage:
cd codas-hep # <-- autojump remembers this
cd ../../my-directory
cd some-subfolder
j codas # <-- get back to codas-hep folder⁉️ Problem: I like visual file managers, but I'm working on a server...
- 💡Solution: Use a terminal file manager, e.g.,
ranger

⁉️ Problem: I search through files a lot, butgrepis slow/inconvenient...
⁉️ Problem: Even with tab completion, completing file names is cumbersome.
- 💡Solution: Try type-ahead-searching/fuzzy matching, e.g., with
fzfwith shell integration, e.g.,vim ../**Tab starts searching withfzfin parent dir
Run small checks before you commit
⁉️ Problem: How can I stop myself from committing low-quality code?
- 💡Solution:
- git hooks allow you to run scripts that are triggered by certain actions
- a pre-commit hook is triggered every time you run
git commit- in principle you can set them up yourself by placing scripts into
.git/hooks
- in principle you can set them up yourself by placing scripts into
::right::
- 🧰 Making it practical:
- The pre-commit framework is a python package that makes configuring pre-commit hooks easy!
- All hooks are configured with a single
.pre-commit-config.yamlfile - Few-clicks GitHub integration available: pre-commit.ci
- 🏗️ Setting it up:
pipx install pre-commitcd <your repo>touch .pre-commit-config.yamlpre-commit install- Profit 🎉
A config that will always be useful. Optional pre-commit.ci CI service.
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: '4.4.0'
hooks:
- id: check-added-large-files
- id: check-case-conflict
- id: check-merge-conflict
- id: detect-private-key
- id: end-of-file-fixer
- id: trailing-whitespace
- repo: https://github.com/codespell-project/codespell # the spell checker with ~0 false positives
rev: 'v2.2.5'
hooks:
- id: codespell
# args: ["-I", "codespell.txt"] # Optional to add exceptions
ci:
autoupdate_schedule: monthly # default is weeklySee Scientific Python Development Guidelines for many more, updated weekly!
# Reformat code without compromises!
- repo: https://github.com/psf/black
rev: '23.7.0'
hooks:
- id: black
# Static checks
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: 'v0.0.278'
hooks:
- id: ruff
args: [--fix, --show-fixes]
# Check typing (slightly more advanced)
- repo: https://github.com/pre-commit/mirrors-mypy
rev: 'v1.4.1'
hooks:
- id: mypy- Try it out: Go here for a quick step-by-step tutorial
⁉️ Problem: Setting up a python package with unit testing/CI/CD, pre-commits, license, packaging information, etc., is a lot of "scaffolding" to be added.
- 💡Solution: Creating templates
- 🧰 Making it practical: cookiecutter is a command line utility for project templates
::right::
-
Example: Scientific Python Cookie: All the features, all the best-practices
-
💡 Pro-tip: cruft is a cookiecutter extension that allows to propagate updates to the template back to the projects that use it
-
💡 Pro-tip: copier is another powerful tool that supports updates (and works with the template above).
-
Trying it out:
pipx install cookiecutter
# alternative: cruft or copier
cookiecutter gh:scientific-python/cookie
# e.g., select project type = hatchling
# for a very simple start that grows with you.⁉️ Problem:- I have some code in a notebook and some code in a python file/library.
- I update my python file/library.
- Do I have to restart the kernel and rerun to see the changes?
- 💡Solution: No! Python supports a number of ways to "reload" imported code.
- Easiest example: Add the following to your Jupyter notebook1 to reload all (!) modules every time you execute code
%load_ext autoreload
%autoreload 2 # reload everything::right::
- More granular:
%load_ext autoreload
%autoreload 1 # <-- reload only some modules
# Mark for reloading
%aimport foo- Warning: These tricks don't always work, but it should save you from a lot of restarts
- Try it out! Follow our instructions here.
- More information: See the autoreload documentation
⁉️ Problem: Tracking & collaborating on Jupyter notebooks with git is a mess because of binary outputs (images) and additional metadata:git diffbecomes unreadable- merge conflicts appear often
- 💡Solutions: You have several options
- Always strip output from notebooks before committing (easy but half-hearted)
- Synchronize Jupyter notebooks and python files; only track python files (slightly more advanced but best option IMO)
- Do not change how you track Jupyter notebooks; change how you compare them (use if you really want to track outputs). Example:
nbdime - Avoid large amounts of code in notebooks so that the issue is less important; create python packages and use hot code reloading instead
Option 1: Track notebooks but strip outputs before committing. Add the following pre-commit hook:
- repo: https://github.com/kynan/nbstripout
rev: 0.6.1
hooks:
- id: nbstripoutOption 2: Synchronize Jupyter notebooks (untracked) to python files (tracked)
pipx install jupytext
echo "*.ipynb" >> ~/.gitignore # <-- tell git to ignore notebooks
jupytext --to py mynotebook.ipynb
# Now you have mynotebook.py
git commit mynotebook.py -m "..."
git push
# People modify the file online
git pull # <-- mynotebook.py got updated
jupytext --sync # <-- update mynotebook.ipynb
# Now make changes to your mynotebook.ipynb
jupytext --sync # <-- now mynotebook.py got updated
git commit ... && git push ...⁉️ Problem: I still have lots of code in my notebooks. I still want to apply tools on notebooks.
-
💡Solution:: Black and Ruff support jupyter notebooks natively!
-
💡 Pro-tip:
nbqaallows other tools to be applied, as well.
# Reformat code without compromises!
- repo: https://github.com/psf/black
rev: '23.7.0'
hooks:
- id: black-jupyter
# Static checks
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: 'v0.0.278'
hooks:
- id: ruff
types_or: [python, pyi, jupyter]
args: [--fix, --show-fixes]⁉️ Problem: I want to preview/run Jupyter notebooks in my terminal.- 💡Solution:
pipx run nbpreviewif you're only interested in previewingpipx run rich-clialso workspipx run nbtermfor interactively executing notebooks in the terminal
⁉️ Problem: Python packages depend on other packages depending on other packages causing a conflict.- 💡Solution: Use conda or virtual environments (
venv,virtualenv,virtualenvwrapper);
The first environment should be named .venv
- The Python Launcher for Unix,
pypicks up.venvautomatically! - Visual Studio Code does too, as do a growing number of other tools.
⁉️ Problem: What aboutpip-installable executables?- 💡Solution: Install them with
pipxinstead ofpip! Examples:pre-commit•black•cookiecutter•uproot-browser
You can also use pipx run to install & execute in one step, cached for a week!
⁉️ Problem: Upgrades can break things.
- ⛔️Not a solution: Don't add upper caps to everything! Only things with 50%+ chance of breaking.
- 💡Solution: Use lockfiles.
Your CI and/or application (including an analysis) should have a completely pinned environment that works. This is not your install requirements for a library!
pip install pip-tools
pip-compile requirements.in # -> requirements.txtNow you get a locked requirements file that can be installed:
pip install -r requirements.txtLocking package managers (pdm, poetry, pipenv) give you this with a nice all-in-one CLI:
pdm init # Setup environment using existing lockfile or general requirements
# Modify pyproject.toml as needed
pdm add numpy # Shortcut for adding to toml + install in venvYou'll also have a pdm.lock file tracking the environment it created.
You can update the locks:
pdm updateRead up on how to use the environment that this makes to run your app.
⁉️ Problem: There are lots of way to setup environments, lots of ways to run things.
- 💡Solution:
- A task runner (nox, tox, hatch) can create a reproducible environment with no setup.
- Nox is nice because it uses Python for configuration, and prints what it is doing.
import nox
@nox.session
def tests(session: nox.Session) -> None:
"""
Run the unit and regular tests.
"""
session.install(".[test]")
session.run("pytest", *session.posargs)Example 1: adapted from PyPA/manylinux
@nox.session(python=["3.9", "3.10", "3.11"])
def update_python_dependencies(session):
session.install("pip-tools")
session.run(
"pip-compile", # Usually just need this
"--generate-hashes",
"requirements.in", # and this
"--upgrade",
"--output-file",
f"requirements{session.python}.txt",
)Example 2: python.packaging.org
@nox.session
def preview(session):
session.install("sphinx-autobuild")
build(session, autobuild=True)::right::
@nox.session(py="3")
def build(session, autobuild=False):
session.install("-r", "requirements.txt")
shutil.rmtree(target_build_dir,
ignore_errors=True)
if autobuild:
command = "sphinx-autobuild"
extra_args = "-H", "0.0.0.0"
else:
command = "sphinx-build"
extra_args = (
"--color",
"--keep-going",
)
session.run(
command, *extra_args,
"-j", "auto",
"-b", "html",
"-n", "-W",
*session.posargs,
"source", "build",
)pytest discovers test functions named test_... in files test_.... For example:
def test_funct():
assert 4 == 2**2To run: pip install pytest and then pytest to discover & run them all.
[tool.pytest.ini_options]
minversion = "6.0" # minimal version of pytest
# report all; check that markers are configured; check that config is OK
addopts = ["-ra", "--strict-markers", "--strict-config"]
xfail_strict = true # tests marked as failing must fail
filterwarnings = ["error"]
log_cli_level = "info"
testpaths = ["tests"] # search for tests in "test" directory--showlocals: Show all the local variables on failure--pdb: Drop directly into a debugger on failure--trace --lf: Run the last failure & start in a debugger- You can also add
breakpoint()in your code to get into a debugger
Reminder: https://learn.scientific-python.org/development/guides/pytest is a great place to look for tips!
def test_approx():
0.3333333333333 == pytest.approx(1 / 3)This works natively on arrays, as well!
def test_raises():
with pytest.raises(ZeroDivisionError):
1 / 0@pytest.mark.skipif(sys.version_info < (3, 8), reason="Requires Python 3.8+")
def test_only_on_38plus():
x = 3
assert f"{x = }" == "x = 3"::right::
There are quite a few built-in fixtures. And you can write more:
@pytest.fixture
def my_complex_object():
mco = MyComplexObject(...)
mco.xyz = "asf"
...
return mco
def test_get_value(my_complex_object):
assert my_complex_object.get_value() == ...
def test_other_property(my_complex_object):
assert my_complex_object.property == ...System IO, GUIs, hardware, slow processes; there are a lot of things that are hard to test! Use monkeypatching to keep your tests fast and "unit".
⁉️ Problem: Compilers catch lots of errors in compiled languages that are runtime errors in Python! Python can't be used for lots of code!
- 💡Solution: Add types and run a type checker.
def f(x: float) -> float:
y = x**2
return y- Functions always have types in and out
- Variable definitions rarely have types
How do we use it? (requires pipx install mypy)
mypy --strict tmp.py
Success: no issues found in 1 source fileSome type checkers: MyPy (Python), Pyright (Microsoft), Pytype (Google), or Pyre (Meta).
👉 Example files available here.
- Adds text - but adds checked content for the reader!
- External vs. internal typing
- Libraries need to provide typing or stubs can be written
- Many stubs are available, and many libraries have types (numpy, for example)
- An active place of development for Python & libraries!
from __future__ import annotations
def f(x: int) -> list[int]:
return list(range(x))
def g(x: str | int) -> None:
if isinstance(x, str):
print("string", x.lower())
else:
print("int", x)But Python is duck-typed! Nooooooo!
Duck typing can be formalized by a Protocol:
from typing import Protocol # or typing_extensions for < 3.8
class Duck(Protocol):
def quack(self) -> str:
...
def pester_duck(a_duck: Duck) -> None:
print(a_duck.quack())
class MyDuck:
def quack(self) -> str:
return "quack"
# Check explicitly that MyDuck is implementing the Duck protocol
if typing.TYPE_CHECKING:
_: Duck = typing.cast(MyDuck, None)- repo: https://github.com/pre-commit/mirrors-mypy
rev: "v1.4.1"
hooks:
- id: mypy
files: src
args: []
additional_dependencies: [numpy]- Args should be empty, or have things you add (pre-commit's default is poor)
- Additional dependencies can exactly control your environment for getting types
- Covers all your code without writing tests
- Including branches that you might forget to run, cases you might for forget to add, etc.
- Adds vital information for your reader following your code
- All mistakes displayed at once, good error messages
- Unlike compiled languages, you can lie if you need to
- You can use
mypycto compile (2-5x speedup for mypy, 2x speedup for black)
Bonus: About a week ago GitHub Actions added direct deploy to pages!
on:
workflow_dispatch:
pull_request:
push:
permissions:
contents: read
pages: write
id-token: write
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true::right::
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Setup Pages
id: pages
uses: actions/configure-pages@v3
# Static site generation, latex, etc. here
- name: Upload artifact
uses: actions/upload-pages-artifact@v2
with:
path: dist/
deploy:
if: github.ref == 'refs/heads/main'
needs: build
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
runs-on: ubuntu-latest
steps:
- name: Deploy to GitHub Pages
id: deployment
uses: actions/deploy-pages@v2⁉️ Problem: You use GitHub Actions for everything. But what if you want to test the run out locally?
- 💡Solution: Use ACT (requires Docker)!
# Install with something like brew install act
act # Runs on: push
act pull_request -j test # runs the test job as if it was a pull requestIf you use a task runner, like nox, you should be able to avoid this most of the time. But it's handy in a pinch! https://github.com/nektos/act
Textualize is one of the fastest growing library families. Rich was even vendored into Pip!
from rich.progress import Progress
import asyncio
async def lots_of_work(n: int, progress: Progress) -> None:
for i in progress.track(range(n), description=f"[red]Computing {n}..."):
await asyncio.sleep(.1)
async def main():
with Progress() as progress:
async with asyncio.TaskGroup() as g:
g.create_task(lots_of_work(40, progress))
g.create_task(lots_of_work(30, progress))
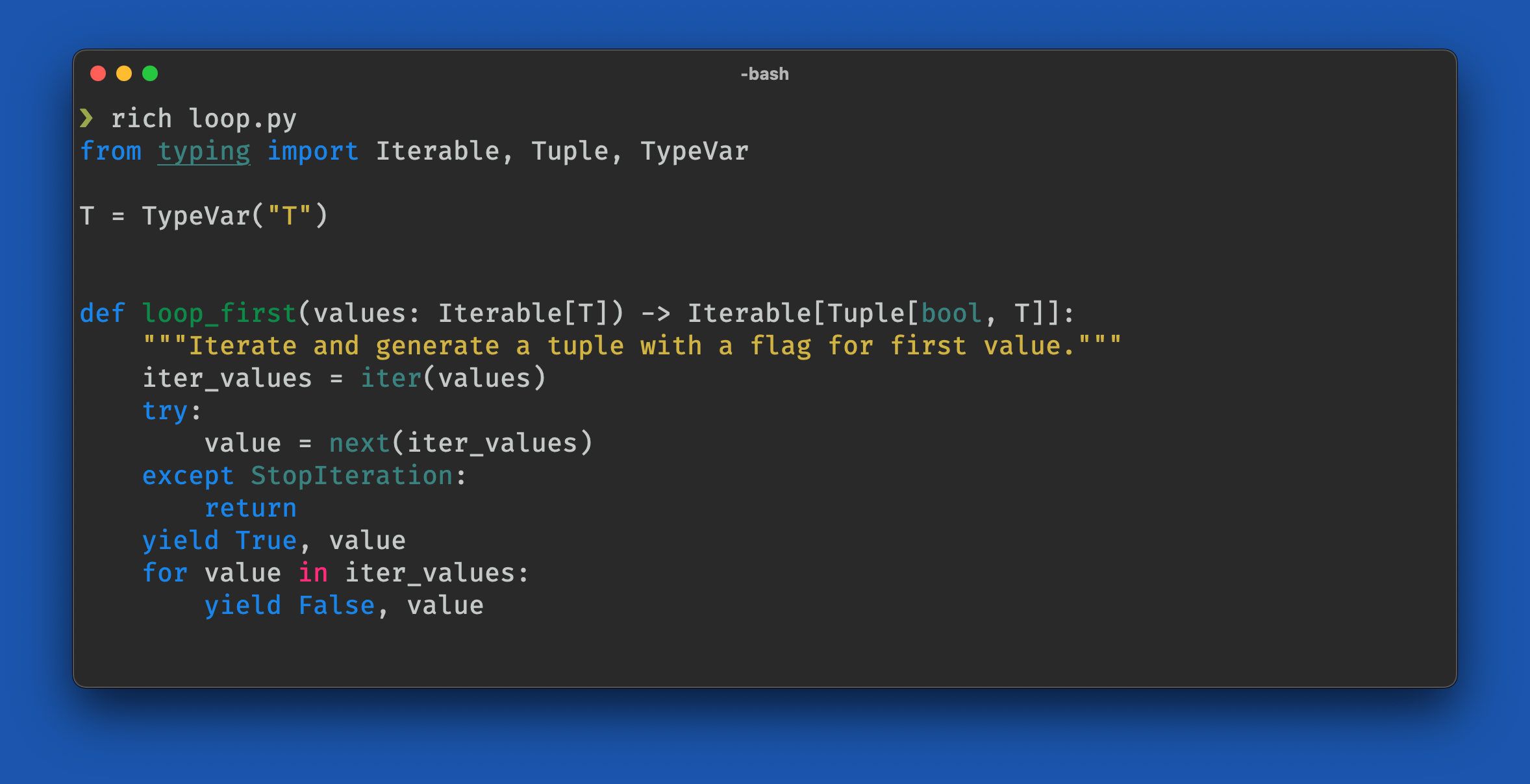
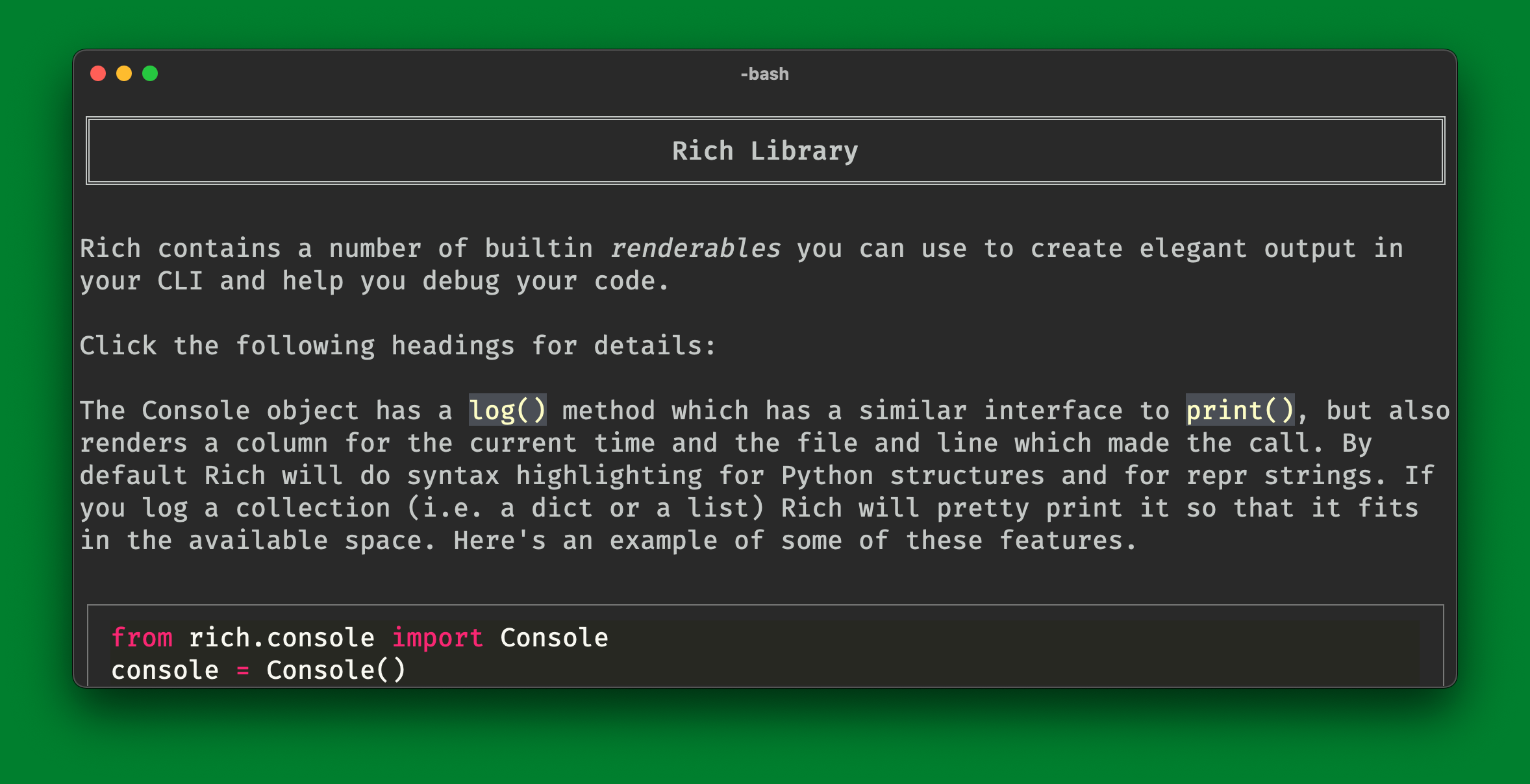
asyncio.run(main())Rich is not just a "color terminal" library.
- Color and styles
- Console markup
- Syntax highlighting
- Tables, panels, trees
- Progress bars and live displays
- Logging handlers
- Inspection
- Traceback formatter
- Render to SVG
::right::


::right::
⁉️ Problem: Distributing code is hard. Binder takes time to start & requires running the code one someone else's machine.
- 💡Solution: Use the browser to run the code with a WebAssembly distribution, like Pyodide. Python 3.11 officially supports it now too!
A distribution of CPython 3.11 including ~100 binary packages like SciPy, Pandas, boost-histogram (Hist), etc.
Examples:
An Python interface for Pyodide in HTML.
---<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello, World!</title>
<link rel="stylesheet" href="https://pyscript.net/latest/pyscript.css" />
<script defer src="https://pyscript.net/latest/pyscript.js"></script>
</head>
<body>
<script type="py-script">
print("Hello, World!")
</script>
</body>
</html>https://docs.pyscript.net/2023.09.1.RC2/beginning-pyscript/
⁉️ Problem: Making a package is hard.
- 💡Solution: It's not hard anymore. You just need to use modern packaging and avoid old examples.
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[project]
name = "package"
version = "0.0.1"Other metadata should go there too, but that's the minimum. See links:
- https://learn.scientific-python.org/development/guides/packaging-simple/
- https://packaging.python.org/en/latest/tutorials/packaging-projects
scientific-python/copier supports 10+ backends; hatching is recommended for pure Python. For compiled extensions: See next slides(s). 😀
⁉️ Problem: Making a package with binaries is hard.
- 💡Solution: I've been working on making it easy!
Use a tool like pybind11, Cython, or MyPyC. It's hard to get the C API right!
#include <pybind11/pybind11.hpp>
int add(int i, int j) {
return i + j;
}
PYBIND11_MODULE(example, m) {
m.def("add", &add);
}Header only, pure C++! No dependencies, no pre-compile step, no new language.
I'm funded to work on scikit-build for three years! CMake for Python packaging.
::right::
Org of several packages:
- Scikit-build
- Scikit-build-core
- CMake for Python
- Ninja for Python
- moderncmakedomain
- Examples
Redistributable wheel builder.
- Targeting macOS 10.9+
- Apple Silicon cross-compiling for 3.8+
- All variants of manylinux (including emulation)
- musllinux
- PyPy 3.7-3.10
- Repairing and testing wheels
- Reproducible pinned defaults (can unpin)
Local runs supported too!
pipx run cibuildwheel --platform linux::right::
on: [push, pull_request]
jobs:
build_wheels:
runs-on: ${{ matrix.os }}
strategy:
matrix:
os:
- ubuntu-latest
- windows-latest
- macos-latest
steps:
- uses: actions/checkout@v3
- name: Build wheels
uses: pypa/[email protected]
- uses: actions/upload-artifact@v3
with:
path: ./wheelhouse/*.whlYou can make a working example with just three files!
cmake_minimum_required(VERSION 3.15...3.26)
project(${SKBUILD_PROJECT_NAME} LANGUAGES CXX)
set(PYBIND11_FINDPYTHON ON)
find_package(pybind11 CONFIG REQUIRED)
pybind11_add_module(_core MODULE src/main.cpp)
install(TARGETS _core DESTINATION ${SKBUILD_PROJECT_NAME})::right::
[build-system]
requires = ["scikit-build-core", "pybind11"]
build-backend = "scikit_build_core.build"
[project]
name = "package"
version = "0.1.0"#include <pybind11/pybind11.h>
int add(int i, int j) { return i + j; }
namespace py = pybind11;
PYBIND11_MODULE(_core, m) {
m.def("add", &add);
}